載入中…
正體中文English
五分鐘心理學2023年10月27日約 18 分鐘
大語言模型其實是一種「序列模型」:它把文字轉成數字,再根據海量人類文本,統計學地預測下一個最可能出現的字,並透過人類反饋的強化學習(RLHF)學會給出人類想要的答案。主持陳健欣由淺入深,解釋ChatGPT如何由「砌出一句通順句子」進化到「理解上文下理」,並說明AutoExpert這類提示詞之所以好用,是因為它先要AI扮演專家、分析問題,再生成答案。他更指出人工智能把原本既不規模化又難預測的人類智慧,變成可規模化、可預測的認知,是一場資訊革命。
如果你問ChatGPT「我可以怎麼學習Python」,它通常會給一些例牌的回應:叫你先了解怎樣學、準備基本設置、找些線上課程。內容不錯,但有點普通——這也是一般人對ChatGPT的印象:有用,卻不夠深入。
但只要按幾個按鍵,再問同一條問題,答案就會大為不同。它會像邀請了一位Python程式專家來分享:步驟仔細很多,例如教你選擇用哪種整合式開發環境(IDE),附上重要的相關超連結,下面還會給實用的Google搜尋連結和網上課程,讓你最容易找到相關資訊。
做法其實很簡單。我最近在GitHub找到一個叫AutoExpert的儲存庫,它是一段如何提示(prompt)ChatGPT的內容。你只需到ChatGPT的客製化指令(Custom Instruction),把那兩段文字分別貼到上下兩個格子,你的ChatGPT就會變成剛才那個好用的版本。
我一直相信生成式人工智能是心理學的未來,也是一項很值得學習的技能。要明白AutoExpert為甚麼這麼有用,先要知道ChatGPT這類大語言模型(Large Language Model)是怎樣運作的。
大語言模型是一種「序列模型」(Sequential Model):輸入是一組字串,輸出也是一組字串。例如輸入是「apple」、指令是翻譯,你預期輸出就是「蘋果」。但在AI那裡,這些文字全部會變成由0和1組成的二進制數字——換言之,對電腦來說全部都是數學:你輸入一組數字,它輸出一組令人類滿意的數字。
那它怎樣生成一句通順的句子?其實這全是統計模型。電腦要處理文字,先要做「代幣化」(Tokenisation),把字詞變成數學代碼——不一定每個字母對一個數字,多數是一個字詞,甚至兩個常一起出現的字(如go to)變成一個Token。以「I go to school by bus」為例,假設I是46、go to是58、school是61、by是5、bus是4,當你給電腦46、58、61、5這個順序,它讀過大量人類文本後,很大機會預測下一個字就是4(bus)。它做的,就是預測最可能出現的下一個字符。
純粹預測下一個字,怎能變成一問一答那麼有趣?這需要兩件事。第一是對話結構:人類文本裡有「劇本」這種形態,專門記錄人與人之間的對話。當你輸入「Q:How are you」「A:」,電腦根據統計學自然會理解接下來應該是上句的答覆,於是學會了對話。
但電腦沒這麼聰明,連人去看人類文本也很困難,所以要把人類智慧植入更多。ChatGPT這類模型會用「人類反饋的強化學習」(RLHF, Reinforcement Learning with Human Feedback)。例如問「How are you」,人類文本有時不那麼和平,可能會答粗口;為甚麼AI會答「I am fine thank you」而不是粗口?這就靠人類回饋:訓練時生成兩個答案,一個有禮、一個無禮,再找一群人標示哪個更好。如此類推不斷重複,AI就學到人類需要甚麼答案。
理解這一點很重要:用大量文本,再加很多人的反饋,我們其實是慢慢把人類的智慧編程進這套模型之中。所以這套模型某程度上是人類智慧的載體。它有沒有意識、感情、真正的智慧,我未必敢說有;但它是否盛載了人類智慧,我很有信心地說它是——就像書本是智慧的載體,而AI是一種很強的智慧載體。
AI最令人驚喜的地方,是它能理解上文下理、跟從很複雜的指令。Siri也會對答,但這種能力是怎樣做到的?它源自Google發表的一篇學術文章《Attention is all you need》,這是AI學術界非常出名的文章,介紹了一個叫Transformer Model的東西。
Transformer模型是在模仿人類處理資訊。以前的人工神經技術有個缺點:沒辦法同時處理或輸出太大量的資訊。Transformer引入「注意力」(attention)的概念,每一時間只需要處理整個輸入和輸出的某部分,令它有強大的理解上文下理能力。
以「I go to school」四個格子為例,下一個格子是甚麼?你會發現每個格子同時收多個輸入:go同時收到I的輸入,school則同時收到to、go、I的輸入——越往後,參考的脈絡越多。這就是理解上文下理的機制。AutoExpert之所以好用,正是運用了這個機制:那段提示詞不是叫AI直接回答,而是先叫它扮演專家、分析這位專家會怎樣處理問題,然後才生成答案;於是最後的答案既根據專家部分的資料,也根據問題部分的資料,自然更仔細實用。
我個人的財政和公司的方向,都押注在人工智能上。為甚麼這項科技這麼具顛覆性?想想以前的工業革命,靠蒸氣機帶來強大動力;現在則是資訊革命,它建基於兩個原則:可規模性(Scalability)和可預測性(Predictability)。
傳統電腦本身就是可規模化的:一個程式寫好,全球可立刻運行,不需太多額外成本,所以傳播得很遠。它也是可預測的:基於精準的程式碼,人類可以完全預計輸出甚麼結果。但瓶頸在於電腦沒有人一樣的認知——一些對人極簡單的工作,例如分辨照片裡是貓還是狗,對以前的電腦來說都極難而不確定,更別說理解文本。
人工智能突破了這道關口。人類智慧在個人層面既不規模化、又難以預測,但當我們把人類智慧和認知凝聚在大語言模型上,就立刻得到可規模化的認知。最新的技術更有「自動生成」(Auto-Gen):多個AI互相對話、思辯,可由零到一自行編寫程式。至於可預測性,AI裡有個叫Temperature的概念,代表隨機性的多少;我們大可把它設為0,讓相同輸入一定產生相同輸出,變成有決定性(Deterministic)的模型。在人類數千年歷史上,我們第一次得到一種可規模化增長的認知,這會打開很多新的可能。
AI可否扮演類似心理學家的角色?眾所周知ChatGPT不太擅長安慰人:你說「我正在考慮要不要辭職」,它會很「GPT」地給你一大堆很普遍的資訊。有人因此說ChatGPT取代不了心理學家。
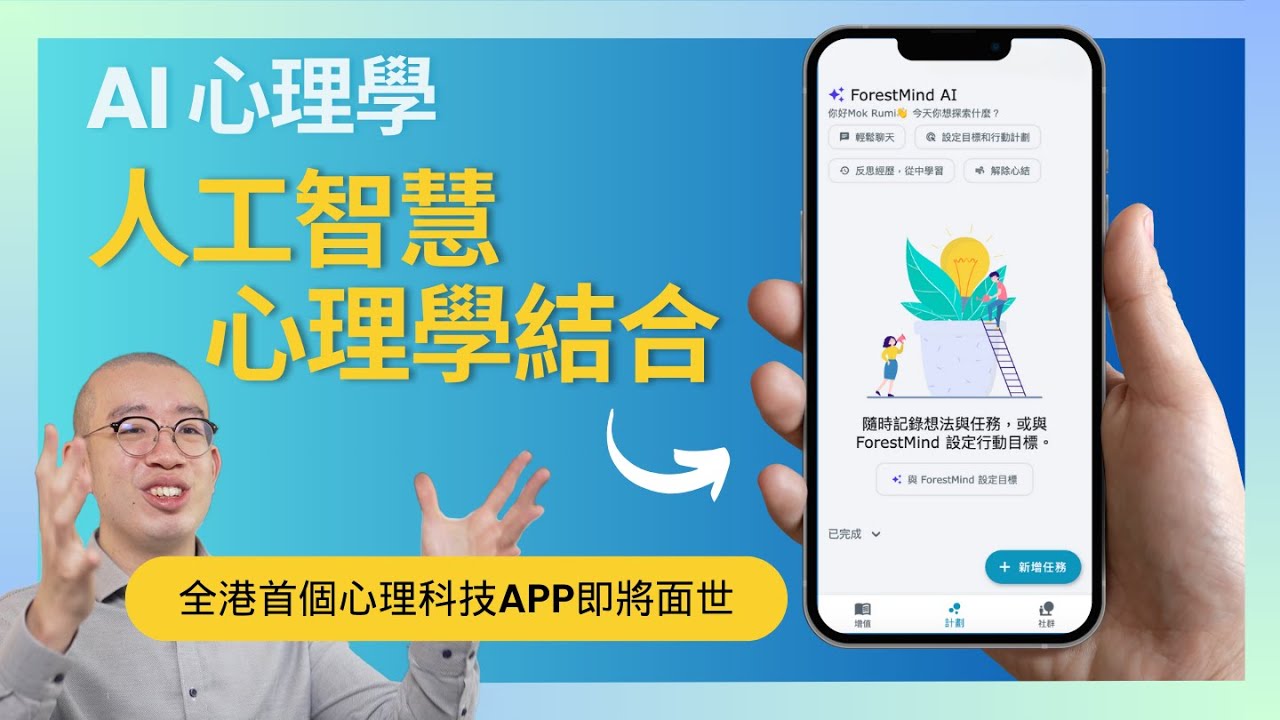
但運用得宜,效果可以很不同。以樹洞香港自主研發的ForestMind AI為例,當我說不知道應不應該辭職,它不會長篇大論,而是像心理學人般反問「你為何會有這個想法」。我繼續說自己未必處理得了手頭的工作,它會回應理解我感到壓力和不安,再追問是工作量太大還是技能不足;甚至可以叫它建議出路,給我務實的建議,例如調整工作範疇或與上司溝通。
我還可以叫它總結對話,把我的經歷和感受寫成一個人生故事,並建議一些實際可做的行為;覺得「與上司溝通」最好,就把它加入清單,再按「計劃下一步」,它便列出該如何溝通的具體步驟。我們仍在調整中,希望它能用廣東話表達。我們深信AI技術可以突破心理行業的關口,幫助每一個人成就更多。
大語言模型本質是一個「序列模型」:輸入是一組字串,輸出也是一組字串。對電腦來說,這些字串全部都是數字——它先把文字「代幣化」(Tokenisation),把字詞變成數學代碼,再根據它閱讀過的大量人類文本,統計地預測下一個最可能出現的字符是甚麼。所謂的「智慧」,其實是建基於這個「預測下一個字」的統計機制之上。
因為人類的文本裡本身就有「劇本」這種形態,專門記錄人與人之間的對話。當你向電腦輸入「Q:How are you」「A:」這樣的結構,它根據統計學自然會理解到接下來應該生成上句的答覆,於是就學會了對話。換言之,對話能力不是電腦額外具備的聰明,而是它從人類對話文本的結構中統計出來的。
純粹預測下一個字會有風險:人類的文字並不總是有禮貌,問「How are you」時,文本裡也可能出現粗口式的回應。RLHF的做法是讓模型生成兩個答案——例如一個有禮、一個無禮——再由一群人標示哪個答案比較好;如此不斷重複,AI就慢慢學會人類真正想要的答案。本質上,這是把人類的價值判斷一點一點地「編程」進模型裡。
主持的立場很審慎:它是否有意識、感情或真正的智慧,他未必敢說有;但他很有信心地說,AI是一個「智慧的載體」。就像書本承載人類智慧一樣,AI透過大量文本加上人類反饋的訓練,把人類的智慧盛載其中,而且是一種非常強的載體。重點不在於它「是不是人」,而在於它承載並能運用人類累積的認知。
關鍵在於Google提出的Transformer模型及其「注意力」(attention)機制。以前的神經網絡無法同時處理太大量的資訊,而注意力機制讓模型每一步只聚焦於輸入和輸出的相關部分,於是每預測一個字,都能同時參考前面多個字的內容。例如生成「school」時,它同時收到「to」「go」「I」的輸入,越往後參考的脈絡越多——這就是它能理解上文下理的原因。
因為這段提示詞不是叫AI直接回答問題,而是先要它扮演一個專家角色、分析這個專家會怎樣處理問題,然後才生成答案。由於AI每預測下一個字都建基於之前的輸入,當「專家身份」和「專家的處理思路」先被寫進脈絡,最後生成的答案就同時根據了專家部分和問題部分的資料,因此會比一般直接作答仔細、實用得多。
主持以工業革命作對比:工業革命靠蒸氣機帶來強大動力,資訊革命則建基於兩個原則——可規模性(Scalability)和可預測性(Predictability)。傳統電腦程式寫好後可全球即時運行、輸出可被精準預計,但瓶頸是電腦缺乏人類般的認知。人工智能突破了這道關口:當人類的智慧與認知凝聚在大語言模型上,原本在個人層面既不規模化、又難以預測的人類認知,第一次變成可以規模化增長、並能調低隨機性(把Temperature設為0)以達致確定性輸出,這在人類數千年歷史上是全新的可能。
主持指出ChatGPT本身不太擅長安慰人——你說「我在考慮要不要辭職」,它往往給你一大堆很普遍的資訊。但這不代表AI無法承擔類似角色:樹洞香港自主研發的ForestMind AI不會長篇大論,而是像心理學人般反問「你為何會有這個想法」,逐步理解你的壓力,再給出務實建議、總結對話、甚至整理成可執行的任務清單。差別不在於技術能否做到,而在於如何運用AI去設計出陪伴與引導的互動方式。
Vaswani et al., “Attention Is All You Need”
Google團隊提出Transformer模型,以「注意力機制」取代過往的循環與卷積結構,讓模型每一步只聚焦於輸入輸出的相關部分,使AI能理解上文下理並跟從複雜指令。
人類反饋的強化學習(RLHF, Reinforcement Learning with Human Feedback)
讓模型生成多個答案,再由人標示哪個較好,反覆訓練,使AI學會人類真正想要、合適而有禮的回應;本質是把人類的價值判斷編程進模型。
序列模型與代幣化(Sequential Model / Tokenisation)
大語言模型把文字代幣化成數字,根據海量人類文本以統計方式預測下一個最可能出現的字符,這是其生成通順句子的基本原理。
自動生成技術(Auto-Gen)
讓多個AI之間互相對話與思辯,可由零開始自行編寫程式,直至產品完成,是大語言模型可規模化能力的延伸應用。
這星期試一次:把你最近一個真實的困擾,先用最普通的方式問ChatGPT,再加上「請你先扮演相關專家、分析這個問題會怎樣處理,然後才回答」的提示,比較兩次答案的分別。留意當你為AI提供更清晰的上文下理時,它的回應如何變得更貼近你的需要——這也提醒我們,好的提問本身就是一種能力。